Sakana Fugu and the End of Model Lock-In
Sakana Fugu routes across frontier LLMs to kill model vendor lock-in. An honest look at the benchmark-vs-reality gap and what it leaves you owning.

Table of Contents
Sakana Fugu is a multi-agent orchestration model from Tokyo-based Sakana AI that routes every request across a swappable pool of frontier LLMs behind one OpenAI-compatible API, sold on a single promise: stop betting your product on one model vendor. Released on June 22, 2026, Fugu Ultra posts a 54.2 on SWE-Pro and 95.1 on GPQA-Diamond, matching Anthropic's Fable and Mythos on those benchmarks without Sakana training a frontier model of its own.
That last part is the whole argument, and also where the trouble starts. Within 24 hours of launch, independent testers reported a sharp gap between the benchmark numbers and how Fugu felt in real work.
Key Takeaways:
- Fugu is an orchestration model, not a new base model. It learns to route tasks across other companies' LLMs and synthesize one answer.
- Its headline value is anti lock-in. If one provider raises prices, hits an export-control wall, or degrades, Fugu routes around it.
- Benchmark scores and real-world feel diverged within a day of launch, and the loudest community question is "router or breakthrough?"
- Fugu solves model-layer lock-in. It does not solve the bigger question of whether you want to be in the orchestration business at all.
- For teams that want outcomes rather than one more API to wire up, a managed agent is a different answer to the same anxiety.
I have spent the past year wiring agent workflows against single-model APIs and feeling every rate limit and price change personally. So I read Fugu's launch less as a benchmark story and more as a lock-in story. Here is what it actually changes, and what it quietly leaves on your plate.
What Sakana Fugu Actually Is
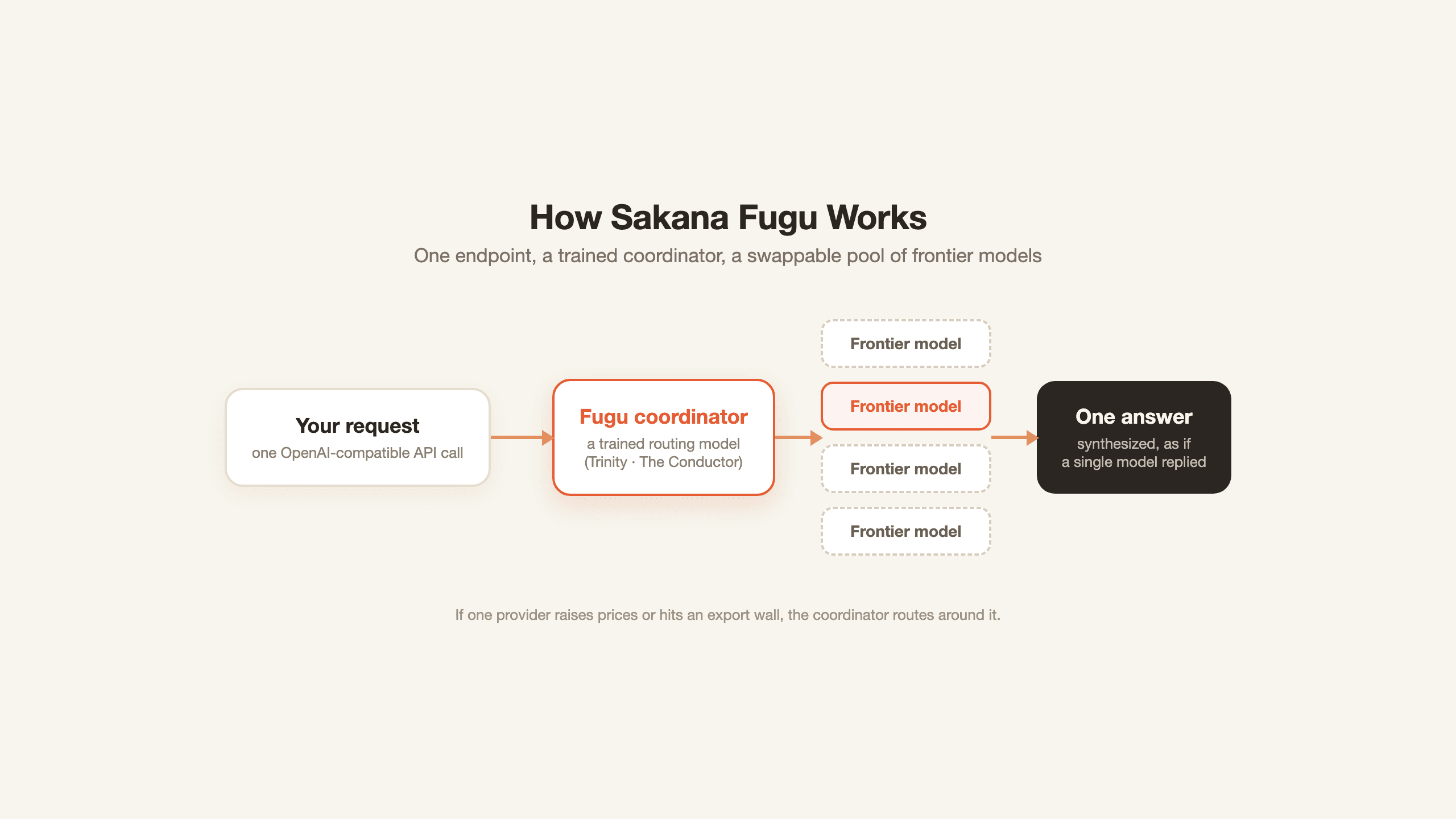
Sakana AI describes Fugu as a multi-agent system that behaves like a single model. You send one request to one endpoint. Fugu decides whether to answer directly or to assemble and coordinate a team of expert models, then hands back one response as if a single model wrote it. There are two variants: Fugu, tuned for a balance of quality and low latency, and Fugu Ultra, for maximum accuracy on demanding multi-step problems. Both speak an OpenAI-compatible API, so adoption is mostly a base-URL swap.
The detail that makes it more than a load balancer is that the coordinator is itself a trained model, not a hand-written if-else over a list of APIs. It builds on two papers Sakana presented at ICLR 2026, Trinity and The Conductor. Trinity is an evolved coordinator that assigns Thinker, Worker, and Verifier roles across a model pool, and The Conductor uses reinforcement learning to discover how a diverse set of models should talk to each other so the group beats any single worker. Fugu productizes that research, moving the orchestration intelligence into the model weights instead of an external script.
VentureBeat framed the launch as "no Claude Fable 5? No problem," which is the pitch in one line: frontier output without depending on any one frontier lab.
What this proved: Orchestration can be packaged as a single callable endpoint, not just a framework you assemble.
What it left unsolved: Calling one smart endpoint is easy. Knowing why it answered the way it did is not, and we will come back to that.
The Vendor Lock-In Problem Fugu Is Aiming At
Single-model dependence is a real operational risk, not a hypothetical. When your product's core feature runs on one provider, that provider's pricing page, rate limits, and regional availability become your roadmap.
Consider Maya, a composite of CTOs I have compared notes with, running a twelve-person legal-tech startup whose contract-review feature was built on a single frontier API. One quarter the provider reworked its pricing, her per-token cost jumped enough to erase the margin on her cheapest plan, and a new rate cap throttled the overnight batch jobs her customers depended on. She had no fallback, because every prompt, eval, and retry path assumed one vendor's quirks.
That is the wound Fugu presses on. As reported in coverage of the launch, Fugu builds redundancy into the stack by orchestrating models from different providers, so a price hike, an outage, or an export-control restriction on one model becomes a routing decision rather than a fire drill. Nikkei Asia noted the export-control angle specifically, which matters more to teams outside the US than the benchmark table does.
What this proved: The lock-in pain is real and widely felt, and an orchestration layer is a coherent response to it.
What it left unsolved: Routing around a vendor only helps if the routing is trustworthy. If you cannot see the routing, you have traded one dependency for another.
Benchmarks vs the Real-World Gap
Here is the honest part the launch-day excitement skipped. The benchmark wins are real, and so is the gap between them and daily use.
Within a day of release, independent testers including Ethan Mollick put Fugu Ultra through messy real tasks rather than clean benchmark prompts. A shader and interactive-scene test took around 30 minutes on Fugu Ultra's high-effort setting, and the output was, in the tester's words, "fine" but did not match Fable in practice. The benchmark table said parity. The hands-on session said something more cautious.
A benchmark score is fair if the question is "which user-facing system gives the best answer," and misleading if the question is "which standalone base model is smartest," because Fugu is not a base model. It borrows other labs' models.
Take Devin, a composite indie developer who swapped his coding assistant to Fugu Ultra expecting a free upgrade from the GPQA number. What he got was slower responses on simple edits, because the coordinator spun up a multi-model deliberation for a task his old model handled in two seconds. Orchestration has overhead, and on easy work that overhead is a tax.
What this proved: Fugu's benchmark parity is legitimate as a system-level result.
What it left unsolved: System-level parity does not mean per-task superiority, and the latency cost of orchestration is real on simple work.
Router or Breakthrough? What the Community Is Actually Saying
The developer reaction split almost immediately, and the split is worth understanding because both sides are partly right.
The skeptical camp formed within hours. The single most upvoted reaction on r/singularity's launch thread, with nearly 200 upvotes, warned people not to assume Sakana had trained frontier intelligence from scratch: Fugu is an orchestrator, a system trained to route and coordinate a pool of other labs' models. Others were blunter, comparing it to OpenRouter-style model fusion and calling it "just another fusion model" that farms work out to the major LLMs and has them check each other. The sharp question underneath all of it: if the models doing the real work belong to other labs, what exactly did Sakana build?
The optimistic camp answers that the coordination layer is itself a trained, RL-tuned model, not a thin dispatcher, and that learning how models collaborate is a genuine contribution. The hands-on reports ran warmer than the hot takes. One developer who actually ran Fugu Ultra shrugged off the label and said it was "pretty good" in practice. A balanced third-party review put the question plainly as "breakthrough or just a wrapper," and concluded that "it's trained" does not fully dissolve the complaint.
The complaint that survives both camps is transparency. Fugu's routing is proprietary and hidden. You cannot see which model answered any given query, the pool is fixed, and you cannot opt a specific model out. For a casual chat that is fine. For a regulated workflow, handing your hardest queries to a black box and trusting it to pick well, without being allowed to look, is a hard sell. MarkTechPost's write-up is careful to frame Fugu as a routing system precisely because that framing sets the right expectations.
What this proved: The trained-coordinator idea is novel enough to be worth taking seriously.
What it left unsolved: Opacity. Anti lock-in loses some of its meaning if you cannot audit what the orchestrator chose.
The Lock-In Fugu Solves, and the One It Doesn't
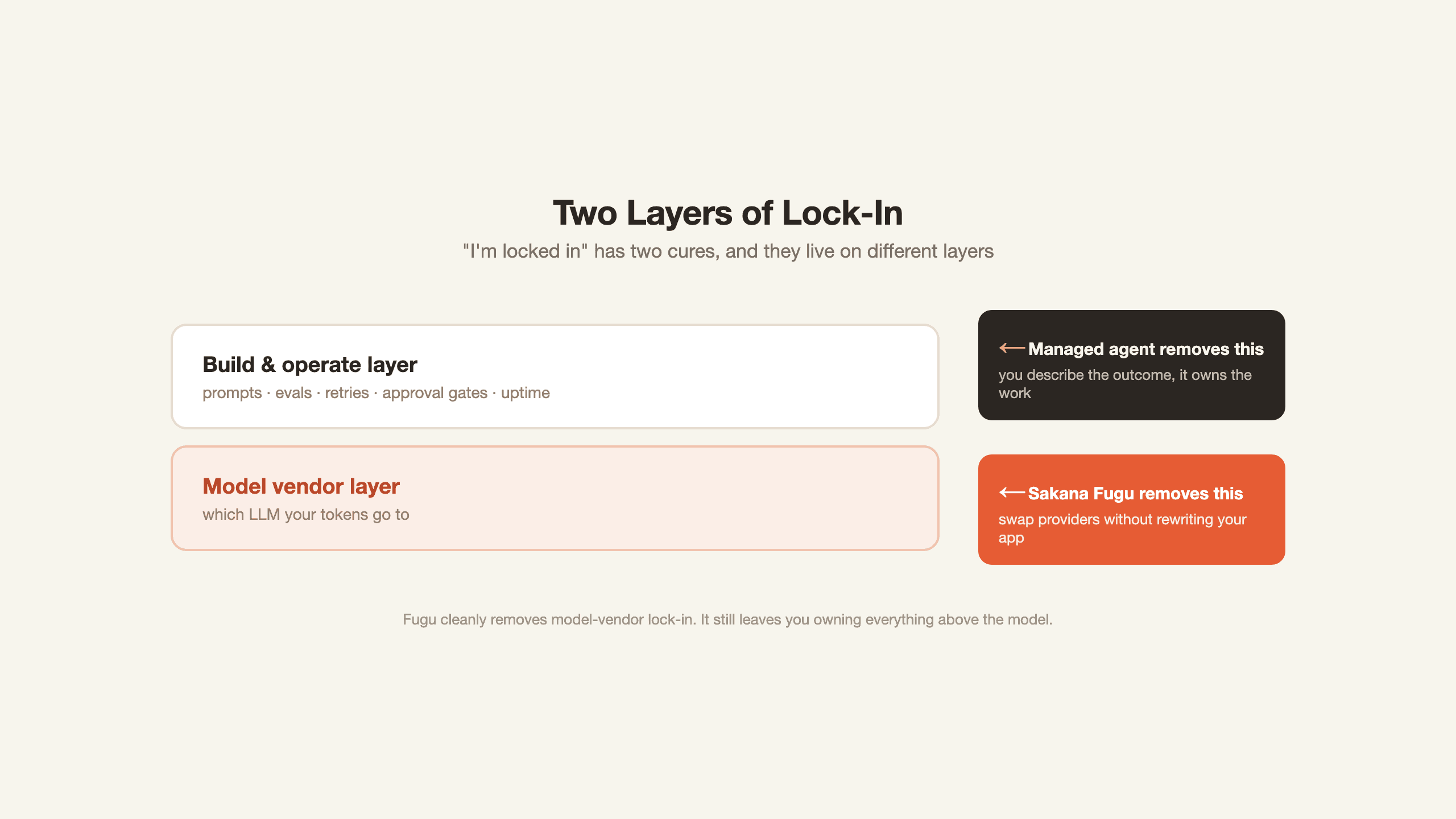
Strip away the launch noise and there are two different kinds of lock-in hiding under one word.
The first is model-layer lock-in: which LLM vendor your tokens flow to. This is the one Fugu attacks directly and well. Swap providers without rewriting your app, dodge a price hike, route around an export rule. If your only problem is "I am too dependent on one model," Fugu is a serious answer.
The second is the one the launch does not mention. Even with Fugu, you still own the application around it. You write the prompts, build the eval harness, wire the retries and approval gates, handle the failures, and keep the whole thing running. Fugu hands you a smarter single endpoint, but you are still the systems integrator. You have swapped model lock-in for a dependency on Sakana's orchestration plus all the glue you still have to build and maintain yourself.
For a meaningful share of buyers, the real question was never "which model." It was "do I want to be assembling any of this in the first place." Think of Priya, a composite operations lead who needs a daily competitor-price digest in Slack and a triaged inbox by 9 AM. She does not want a model router. She wants the task done, on a schedule, with someone else owning uptime. An orchestration API does not solve her problem, because her problem starts one layer up from the model.
What this proved: Fugu cleanly removes model-layer lock-in.
What it left unsolved: The build-and-operate burden, which for many teams is the larger cost.
Orchestration API vs Managed Agent: Pick by What You Want to Own
The useful way to choose is not by benchmark, it is by which layer you want to stop owning. Here is how the options actually line up.
| Layer you call | What you call | What you still build and run | Lock-in it removes | Best for |
|---|---|---|---|---|
| Raw single-model API | One vendor endpoint | Everything: routing, prompts, ops | None | Teams wanting full control and one known model |
| Sakana Fugu | One orchestration endpoint | The whole app around it | Model-vendor lock-in | Builders who want frontier output without single-lab dependence |
| Self-hosted framework (LangGraph, CrewAI) | Your own orchestration code | Routing logic plus all ops | Some model lock-in, full control | Engineering teams with capacity to own the stack |
| Managed agent platform (MoClaw) | A described outcome | Almost nothing operationally | Build-and-operate burden | Teams that want the task done, not a stack to maintain |
MoClaw sits at the far end of that table on purpose. It is a cloud-hosted take on the OpenClaw agent framework, with managed infrastructure, a skills marketplace, memory, and native multi-channel messaging. You describe the job in plain English and it runs on a schedule across Slack, email, WhatsApp, or Telegram, with no model to choose or orchestration graph to wire. That is a different product from Fugu, aimed at a different buyer. The point is not that one wins, but that "I am locked in" has at least two cures living on different layers. If you are weighing the agent layer specifically, our breakdown of real AI agent use cases in 2026 covers what actually survives production.
What this proved: Lock-in is a layered problem, and the right tool depends on the layer you want to abandon.
What it left unsolved: No single product covers every layer, so the honest answer is to name your layer first.
FAQ
Is Sakana Fugu a new AI model or a router?
Both, depending on framing. The coordinator is a trained, RL-tuned model that learns how to route and combine other models, so it is not a thin dispatcher. But the heavy reasoning is done by frontier LLMs from other labs, so calling Fugu a sophisticated orchestration layer rather than a new base model is also accurate.
Does Sakana Fugu actually beat Claude Fable 5?
On certain benchmarks Fugu Ultra matches Fable and Mythos, scoring 54.2 on SWE-Pro and 95.1 on GPQA-Diamond. In hands-on testing within 24 hours of launch, independent reviewers found the real-world feel did not fully match Fable, especially on latency for simple tasks. Benchmark parity and daily-use parity are not the same thing.
How does Fugu help with vendor lock-in?
By routing each request across a pool of models from different providers behind one API. If a provider raises prices, has an outage, or faces an export-control restriction, Fugu can route to another model without you rewriting your application's model integration.
Can I see which model answered my Fugu request?
No. The routing is proprietary, the model pool is fixed, and you cannot opt out specific models or inspect which one handled a given query. That opacity is the most common criticism from developers evaluating it for regulated or auditable workflows.
When should I use a managed agent instead of an orchestration API?
When your goal is a finished task on a schedule rather than a model endpoint to build on. Fugu still leaves you owning the application, prompts, evals, and operations. A managed agent platform owns that layer for you, which suits operators who want outcomes over infrastructure.
What Sakana Fugu Changes for How You Choose an AI Stack
Fugu's real contribution is not the benchmark table, it is reframing the AI stack around a question more teams should ask out loud: which layer am I willing to keep owning? It makes model-vendor lock-in feel optional, which is genuinely useful for anyone building directly on frontier APIs. It also quietly proves the opposite case: the moment you adopt it you are still the integrator of everything above the model, now with a black-box router in the middle.
So choose by layer, not by headline. If you build products and your pain is single-model dependence, Fugu is worth a serious trial, with eyes open about latency on easy tasks and the lack of routing transparency. If your pain is that you are assembling and operating an agent at all, the answer is not a smarter model endpoint, it is a managed agent that owns the work end to end. The smartest move in 2026 is not picking the model that tops a leaderboard this week. It is deciding which layer of the stack you never want to babysit again, and buying exactly that.
Continue Reading
More Research
What Autonomous AI Agents Should Handle

OpenSquilla: Token-Efficient AI Agents

MoneyPrinterTurbo: Workflow Lessons for AI Agents

Kimi WebBridge: Browser Agents That Reuse Work

Kimi Agent Swarm and Claw Groups Explained

AI Automation ROI in 2026: The Numbers Behind 171 Percent
Field notes from the MoClaw team. We compare the agent stack we run in production against the alternatives we evaluated and dropped. Production stories with real numbers, not vendor decks.
Turn insights into action.
MoClaw automates the recurring work your analysis points to. No engineering required.
References: Sakana AI: Fugu Release · Sakana Fugu Product Page · The Decoder: Fugu Orchestrates Multiple LLMs · VentureBeat: Sakana Fugu Multi-Model System · Nikkei Asia: Sakana Fugu Scores Against Fable 5 · ExplainX: Sakana Fugu Benchmarks vs Real-World Testing · Sakana Fugu Review: Breakthrough or Just a Wrapper? · AI News: Mitigating Vendor Lock-In with Sakana Fugu · MarkTechPost: Sakana Fugu Routes Across Frontier LLMs · r/singularity: New Japanese model on par with frontier American models (launch discussion) · r/vibecoding: Has anyone tried Sakana Fugu Ultra yet? · OpenRouter (model routing marketplace)