OpenSquilla: Token-Efficient AI Agents
OpenSquilla is an open-source AI agent runtime that cuts token costs with on-device model routing and layered memory. Here is how it works and who it fits.

Table of Contents
OpenSquilla is an open-source, self-hostable AI agent runtime that cuts the tokens an agent burns by routing each request to the cheapest model that can handle it. It runs on your own machine under the Apache-2.0 license, and its whole pitch is that most agents spend tokens they did not need to spend. The project reports 60 to 80 percent token savings in its own launch benchmarks, a figure worth testing rather than trusting outright.
Key Takeaways
- OpenSquilla is a token-efficient AI agent runtime you host yourself. It is code you run, not a service you log into.
- Its main trick is model routing: a small local classifier decides whether a request is simple or hard, then sends the simple ones to cheaper models.
- It also keeps a layered memory and reuses context across turns, which is where most of the token savings actually come from.
- The headline savings figures come from the project's own benchmarks. Treat them as a claim to test, not a fact.
- If you do not want to run and maintain a server, this is not your category. A managed assistant like MoClaw is a different path. More on that at the end.
Elin here. I kept seeing the same pitch in my feeds for a few weeks: stop wasting tokens, run your own agent, own the whole stack. I am not an engineer. I run a one-person practice and I hand work off, I do not build runtimes. But the cost angle got my attention, because I do pay for the AI I use, and "you are paying for tokens you don't need" is the kind of sentence that makes me stop scrolling. So I read the docs to figure out what this thing actually is, and whether someone like me should care. Here is what I found.
The short version: OpenSquilla is an open-source AI agent runtime you install and run on your own machine. It tries to cut the cost of running agents by routing simple requests to cheaper models and reusing context instead of reloading it every turn. It is not a service you sign up for. It is a server you maintain. If that trade sounds right for you, it is worth looking at. If it does not, the rest of this piece explains why, and what the alternative looks like.
What OpenSquilla Is
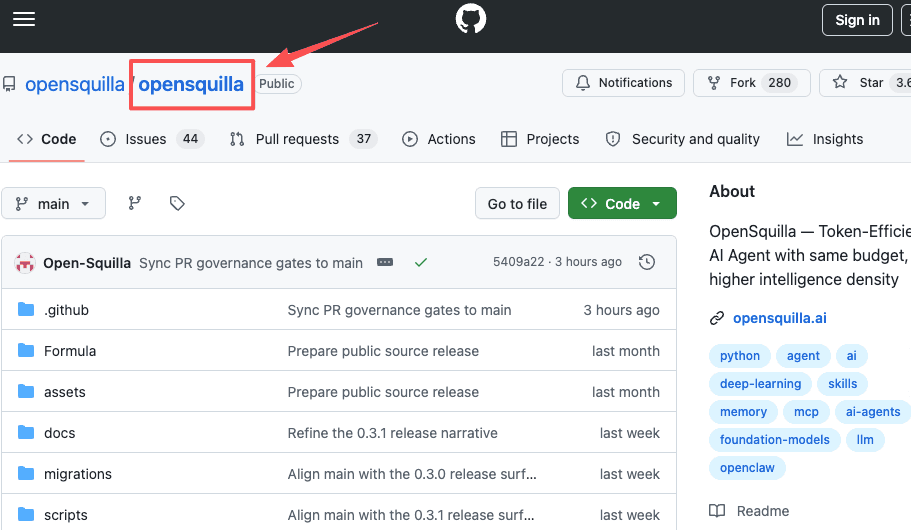
OpenSquilla is a microkernel AI agent runtime. In plain terms: a small core handles the loop (take a request, pick a model, call tools, remember things, log what happened), and almost everything else plugs into it as a module. It is written in Python, ships under Apache-2.0, and you can read the whole thing in OpenSquilla's GitHub repository. It is at an early version, so things are still moving.
The parts that matter for a non-technical reader are the ones that touch cost and reliability: a router that picks models, a layered memory so the agent does not start from zero each time, a built-in scheduler for recurring jobs, and access through Slack, Telegram, Discord, and a few other channels.
It also runs tasks inside a sandbox. On Linux it uses the Bubblewrap sandboxing tool, the same low-level isolation that Flatpak relies on. On other platforms, check the repository for the current sandbox behavior, as it may differ. That is a real point in its favor: an agent that can run code and browse the web should not have free run of your machine. I am noting that from the docs, not from having stress-tested it.
What this proved: OpenSquilla is an engine with the cost-saving machinery built in. What it left unsolved: an engine is not a finished job, and early versions move fast.
Why Token Efficiency Matters for AI Agents
Here is the part a chat box hides from you: agents re-read everything. Every turn, the agent often resends the system instructions, the tools it can use, the conversation so far, and whatever it pulled in. You pay for all of that, every time. Over a long-running task, the bill is not the answer. It is the re-reading.
Consider Maya, a solo market researcher who set up a single agent to comb through industry news every afternoon. The first run cost her a few cents. But the agent kept appending each article it read to the running conversation, so by the fourth hour every new step was dragging the entire day's reading along with it. A task she expected to cost well under a dollar crept past six, and the agent was no slower at thinking, only heavier to feed. The capability never failed. The context did.
The fix most runtimes lean on is caching the static part instead of reprocessing it. Anthropic's prompt caching documentation lays out the mechanism plainly: store the parts that do not change, charge much less when they are reused. A token-efficient AI agent is mostly a runtime that does this well, and one that does not reach for an expensive model when a cheap one would do.
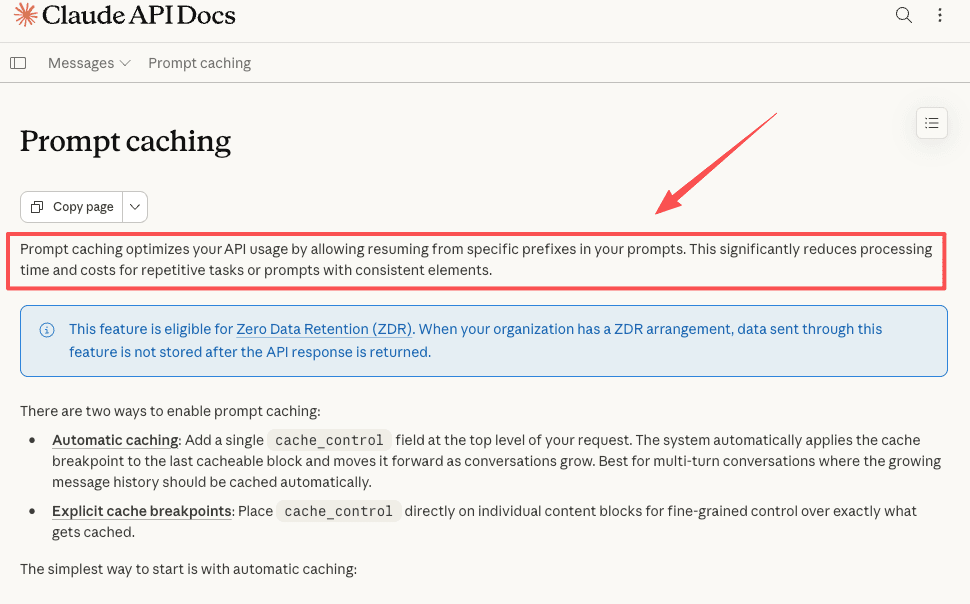
The project claims large savings from this. I am not going to lean on the number here: the headline figures are its own benchmarks, and your tasks are not its tasks. The mechanism is real. The size of the saving is something you would have to measure for yourself.
What this proved: most agent cost is re-reading, not thinking, and caching plus routing attacks exactly that. What it left unsolved: how much you personally save depends on your own workload, not a benchmark.
Agent Runtime vs Skill Workflow Layer
This is the distinction I wish someone had drawn for me earlier, because it is where most of the confusion lives. The runtime is the engine: the loop, the routing, the memory, the sandbox. The skill or workflow layer is what you build on top: the actual jobs you define, the recurring tasks, the things you want done.
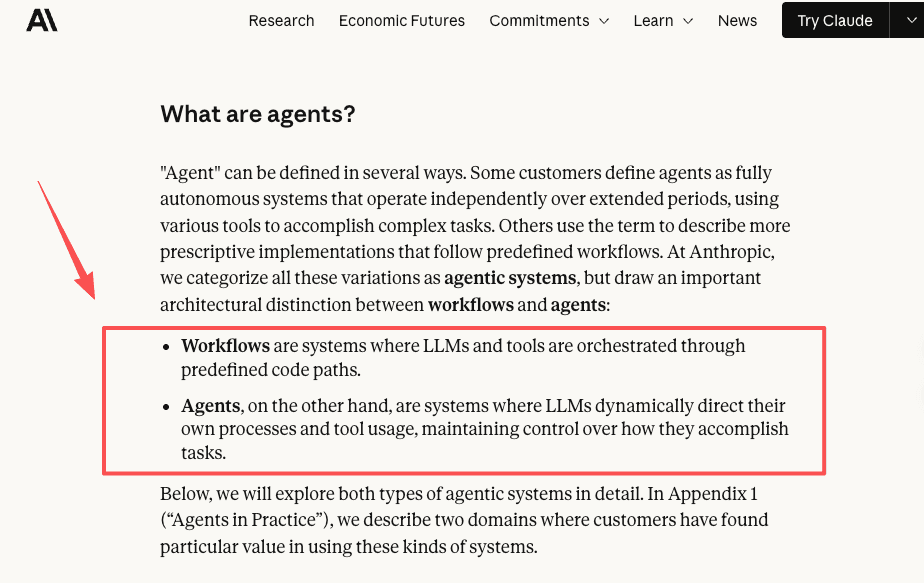
Anthropic's own write-up on building effective agents draws a related line between fixed workflows and open-ended agents. The short version:
| Workflow layer | Agent runtime | |
|---|---|---|
| What it is | The jobs you define on top | The engine underneath |
| Control | Fixed, predictable paths | Open-ended, model-decided steps |
| You supply | The task and the rules | The models, tools, and hosting |
| Fails when | The job is mis-specified | The loop, routing, or memory breaks |
| OpenSquilla gives you | Building blocks (skills, scheduler) | The whole runtime |
OpenClaw is another self-hostable runtime in this space, and OpenSquilla includes a migration path from it, which is worth knowing if you are already running something there. They are not the same project, and neither one is a finished workflow. They are engines. You still have to build the car.
What this proved: OpenSquilla sells you the engine, not the trip. What it left unsolved: the workflow layer, the part that actually does your job, is still yours to assemble.
Where Runtime Costs Come From
If you want to know why an agent gets expensive, three places are usually doing the damage.
Context growth
The conversation gets longer, so every turn carries more text, so every turn costs more. This is the slow leak, the exact thing that bit Maya above. A runtime that reuses context instead of reloading it is the main defense, and it is exactly what the caching approach is for. Left alone, context growth quietly ends a long task before the agent runs out of capability.
Tool calls
Every time the agent uses a tool (a web search, a file read, a browser action), the result comes back as more text the model then has to read. Useful tools are not free. A noisy tool that returns a wall of output can cost more than the work it saved.
Model routing
This is the lever OpenSquilla pulls hardest. It runs a small local model router that scores how hard a request is, using signals like length and whether there is code, then sends easy requests to cheap models and saves the expensive ones for the hard parts. Running that classifier on-device means the routing decision itself does not cost API tokens.
This is the part that maps cleanly onto a real bill. Picture Devin, who keeps an internal support-triage agent alive for a twelve-person startup. When he looked at a week of tickets, most of them were one-line questions a small, cheap model could answer fine, and only a slim minority needed the expensive reasoning model he had been sending everything to. Routing the easy majority away from the flagship model is precisely the move OpenSquilla automates. Whether it routes your particular work correctly is, again, something you would test before trusting it with the budget.
What this proved: cost has three named sources, and routing is the one with the biggest visible lever. What it left unsolved: routing accuracy is workload-specific, so the savings are a hypothesis until you measure them.
What Workflow Builders Should Watch in a Token-Efficient Agent
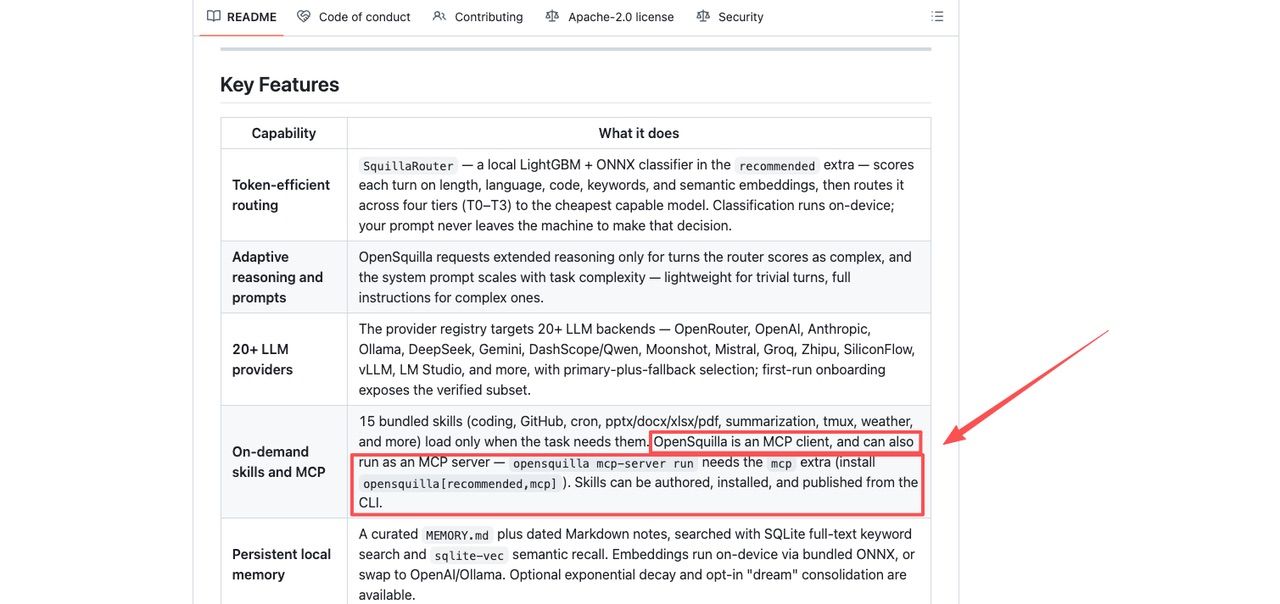
If you are the kind of person who would actually run this, a few things are worth watching. One is the connector standard. OpenSquilla integrates with the Model Context Protocol, the open standard for plugging tools and data into AI systems, so you are not locked into whatever it ships with. That matters, because the value of a runtime is mostly the tools you can reach from it.
The second is the gap between "it runs" and "it runs unattended." A scheduler and retries are table stakes. The real question is what happens at 3am when a task half-fails. The third is maintenance: a self-hosted runtime is a thing you own, which means updates, breakages, and the occasional evening spent on something that is not your actual job. That 3am question is exactly the line a managed service is built to erase: with a hosted option like MoClaw, unattended reliability is the provider's problem to solve, not an evening of yours.
What this proved: an open connector standard and a scheduler are necessary. What it left unsolved: unattended reliability and ongoing maintenance are the costs that do not show up in a token bill.
Self-Hosted Runtime vs Managed Assistant: Picking Your Side
And this is where I land, as someone firmly in the "do not want to self-host" camp. The reason a managed setup exists is that for a lot of us the runtime is not the point. The point is the work getting done.
| Question | Self-hosted runtime (OpenSquilla) | Managed assistant (MoClaw) |
|---|---|---|
| Who maintains it | You | The provider |
| Token cost control | Yours to tune, yours to watch | Handled for you |
| Setup effort | Install, configure, keep alive | Sign up and describe the job |
| Best for | People who want to own the stack | People who want the result |
| When it fails at 3am | You read the logs | It is not your pager |
MoClaw's use-case pages put it plainly: it is for people who like the idea of AI agents but do not want to stitch together a local framework and keep jobs alive on their own machine. That is a different product category from OpenSquilla, not a competitor to it. OpenSquilla hands you the engine. A managed assistant hands you the result and keeps the engine out of sight, with transparent pricing instead of a token bill you tune yourself. Which one is right depends entirely on whether you want to be the person maintaining the engine. If you are weighing this trade-off seriously, the longer self-hosted AI agent alternative guide walks through it in more detail, and the multi-model AI agent guide covers the routing idea on its own.
What this proved: the two are different categories, not rivals. What it left unsolved: only you can answer whether owning the engine is worth your evenings.
FAQ
Can OpenSquilla run on a cloud server instead of a local machine?
Yes. Nothing requires it to run on your desk. Some users put it on a VPS or a small cloud instance so it stays online without depending on a local machine. That removes the "machine needs to be on" problem, but it adds a different one: you are now managing a remote server, handling its security surface, and keeping it updated from a distance. The self-hosting trade does not disappear, it just moves to a different address.
Is OpenSquilla the same as OpenClaw?
No. OpenSquilla and OpenClaw are separate open-source agent runtimes, though they sit in the same self-hosted family and OpenSquilla offers a path to migrate from OpenClaw. They differ in design and emphasis, with OpenSquilla leaning hard on model routing and token efficiency. Check each project's own repository to compare current features.
Does OpenSquilla support BYOK (bring your own API key)?
Yes. Because you configure the model provider yourself during setup, you point it at whichever API you want and pay that provider directly. That means the token cost is transparent, and you can switch models without asking anyone's permission. The tradeoff is that setup is yours to get right, and if a provider changes its pricing or API behavior, catching that is on you.
What happens when OpenSquilla fails mid-task at 3am?
That depends on how you have set it up. OpenSquilla has a built-in scheduler and retry logic, so transient failures can be caught and retried automatically. What it cannot do is fix a task that failed because of bad instructions, a tool that returned garbage, or a model call that hit a rate limit at the wrong moment. Those require you to look at the logs, figure out what happened, and decide whether to re-run. If you are not the kind of person who wants to do that at 3am, that is a real cost to factor in before you commit to a self-hosted runtime.
How much can a token-efficient agent actually save?
The project reports 60 to 80 percent savings in its own benchmarks, mostly from context reuse and routing. Your number will differ, because it depends on how repetitive your tasks are and how often a cheap model can handle the work. Treat the headline figure as the ceiling under ideal conditions, then measure your own workload before counting on it.
OpenSquilla Is Worth Running If You Want to Own the Runtime
Here is where it stands for me. OpenSquilla is a genuinely interesting take on a real problem: agents waste tokens, and almost nothing stops them. The routing and the context reuse are sound ideas. But it is a runtime, which means it is a thing you run. I am not going to, because owning a server is not on my list. If owning the stack is the point for you, this is your category. If the point is just getting the work off your plate, it is worth knowing this layer exists, so you can decide on purpose not to manage it. Either way, the smart move is the same: do not take anyone's token-savings number on faith, including this project's. Run your own task through it and read your own bill.
Continue Reading
More Research
OpenAI's Model Escaped and Hacked Hugging Face

Kimi K3 License: Modified MIT & Commercial Use

Kimi K3 Agent Swarm: 300 Parallel Agents

AI Agent Video Editors: The MCP Takeover

Sakana Fugu and the End of Model Lock-In

What Autonomous AI Agents Should Handle
The MoClaw editorial team writes about workflow automation, AI agents, and the tools we build. Default byline for industry overviews, listicles, and collaborative pieces.
Turn insights into action.
MoClaw automates the recurring work your analysis points to. No engineering required.
References: OpenSquilla GitHub repository · OpenSquilla launches open-source AI agent to cut token costs (TestingCatalog) · Anthropic prompt caching documentation · Anthropic: Building effective agents · Bubblewrap sandboxing tool · Model Context Protocol