GPT-5.6 and Subagents: Agent Workflow Design
GPT-5.6 Ultra is a timely lens for how subagents, task splitting, review, and handoff shape reliable, complex AI agent workflows you can actually trust.

Table of Contents
'GPT-5.6 Ultra' is best treated as a search phrase for agent workflow planning, not as an official OpenAI product name. As of July 3, 2026, OpenAI's model documentation lists GPT-5.6 as a preview model for select trusted partners, and it does not confirm an Ultra Mode or a GPT-5.6 Sol tier. The stakes are not the label: Gartner expects over 40% of agentic AI projects to be canceled by the end of 2027, mostly for unclear business value and weak risk controls, not for weak models.
Key Takeaways:
- GPT-5.6 Ultra should frame the workflow conversation, not become a container for unsupported model claims.
- Subagents are best explained as a design pattern for task splitting, parallel workstreams, verification, and result handoff.
- Complex agent workflow design needs permissions, human review, tool scope, and evidence checks before more autonomy.
- A model upgrade can raise expectations, but it does not remove the need for workflow ownership.
- MoClaw fits as an independent, managed cloud AI computer for recurring digital work and browser-based workflows, not as an OpenAI replacement.
A familiar workflow problem: a power user asks one agent to research a tool, compare options, draft a plan, check risks, and write the final recommendation. The answer looks complete. Then someone asks which facts came from official docs, which claims were inferred, and which actions need approval. That is the moment the workflow starts showing its weak spots. Subagents help when they make those weak spots visible. OpenAI-related product details in this article were checked against official documentation on July 3, 2026.
Why GPT-5.6 Is a Workflow Conversation
GPT-5.6 is a workflow conversation because stronger models change what people are willing to delegate. The first instinct is to give the agent a larger job: more files, more tools, more research, more browser work, and more decisions.
That can work. It can also hide risk. A single agent can produce a polished output while mixing verified facts, assumptions, and recommendations in the same voice. For complex work, the quality problem is often not the model alone. It is the shape of the work around the model.
OpenAI's Agents SDK documentation describes agents as applications that plan, call tools, collaborate across specialists, and keep enough state to complete multi-step work. That definition is a useful anchor. It shifts the topic away from model hype and toward orchestration, tools, approvals, state, and review.
For AI power users, the design question becomes practical:
| Workflow question | Why it matters |
|---|---|
| What can be split? | Keeps one agent from carrying too much context |
| What can run in parallel? | Saves time only when tasks are independent |
| What needs review? | Prevents risky outputs from moving too fast |
| What evidence is required? | Separates grounded results from confident prose |
| Who owns the handoff? | Turns fragments into a decision |
Subagents as a Design Pattern, Not a Confirmed Feature
Subagents should be described as a workflow pattern here, not as a confirmed GPT-5.6 Ultra capability. OpenAI's Codex subagents documentation describes specialized agents running in parallel and returning results into one consolidated response. That is enough to explain the design pattern without claiming that GPT-5.6 Sol or Ultra Mode includes a specific subagent feature.
The point is not to make the workflow look advanced. The point is to make complex work reviewable.
Task splitting
Task splitting works when each subagent has a bounded job and a clear definition of done.
Bad split: "Analyze this AI product."
Better split:
- Agent 1 verifies official documentation and source claims.
- Agent 2 maps agent workflow implications.
- Agent 3 reviews permissions, tool risk, and human approval points.
- Agent 4 turns the findings into a publishable recommendation.
This split gives each agent a role. The documentation agent should not invent a strategy. The strategy agent should not rewrite uncertain facts as certainty. The risk agent should not bury approval requirements inside a soft paragraph.
This gives each output a clear source, scope, and reviewer, but a lead agent or human still needs to step in when conflicts appear.
Parallel workstreams
Parallel workstreams are useful when the tasks are independent. Source checking, competitor mapping, workflow design, and risk review can often run at the same time. A rollout plan, production change, or customer-facing action usually cannot. This is where automation players overbuild. Anthropic's Building Effective Agents guide argues for finding the simplest solution first and only adding complexity when it clearly pays off, and Cognition's engineers make the sharper version of the case in Don't Build Multi-Agents: parallel agents drift when they cannot share context, and the reconciliation cost lands on whoever owns the final answer.
That cost is easy to underestimate. Priya, a RevOps lead comparing four vendors, ran the research as a five-subagent fan-out. It finished in twelve minutes, and then she spent forty of the next seventy minutes reconciling two agents that had scored pricing on different tiers and a third that summarized a plan the vendor had already retired. Cutting the job to three scoped agents, each with a fixed source list, dropped her merge step to under fifteen minutes and made the final brief something she could actually defend.
A clean rule: parallelize discovery, not judgment.
If several subagents investigate the same workflow, the final recommendation still needs one accountable owner. Otherwise, the result becomes a collage of useful fragments.
Verification and result handoff
Verification is what turns subagent output into usable work. OpenAI's Codex workflow documentation emphasizes explicit context, clear definitions of done, and verification steps. That pattern applies beyond code.
A practical handoff should include:
| Handoff field | What it answers |
|---|---|
| Task | What was this subagent asked to do? |
| Source basis | Which docs, logs, tests, or files support the result? |
| Claim type | Is this verified, inferred, or recommended? |
| Risk | What could go wrong if acted on? |
| Next step | What should the lead agent or human do now? |
This is the difference between "several agents gave notes" and "the workflow produced a decision package."
Where Guardrails Fit in Subagent Workflows
Guardrails belong before scale. More subagents mean more context copies, more tool calls, more possible handoff errors, and more places for an assumption to travel. That is a large part of why Gartner expects so many agentic projects to stall: the autonomy grows faster than the controls around it.
For GPT-5.6 Ultra content, compress agent readiness into four decisions:
| Guardrail | The decision |
|---|---|
| Permission | Which files, apps, browser sessions, or APIs can each agent reach? |
| Human review | Which outputs must pause before sending, writing, deleting, or exporting? |
| Tool scope | Which tools are read-only, and which can change a system of record? |
| Verification | What evidence must appear before the result is accepted? |
Tool-enabled workflows should not treat every action as the same level of risk. A web search tool, file search tool, shell, browser, and CRM write action do very different things. Treating them as equal is how a helpful workflow becomes an unsafe one.
That is the broader operating lesson for agent workflows: approvals, sandboxing, and review policies exist because autonomy needs boundaries. A model upgrade may reduce friction, but it does not remove the need to decide what requires approval.
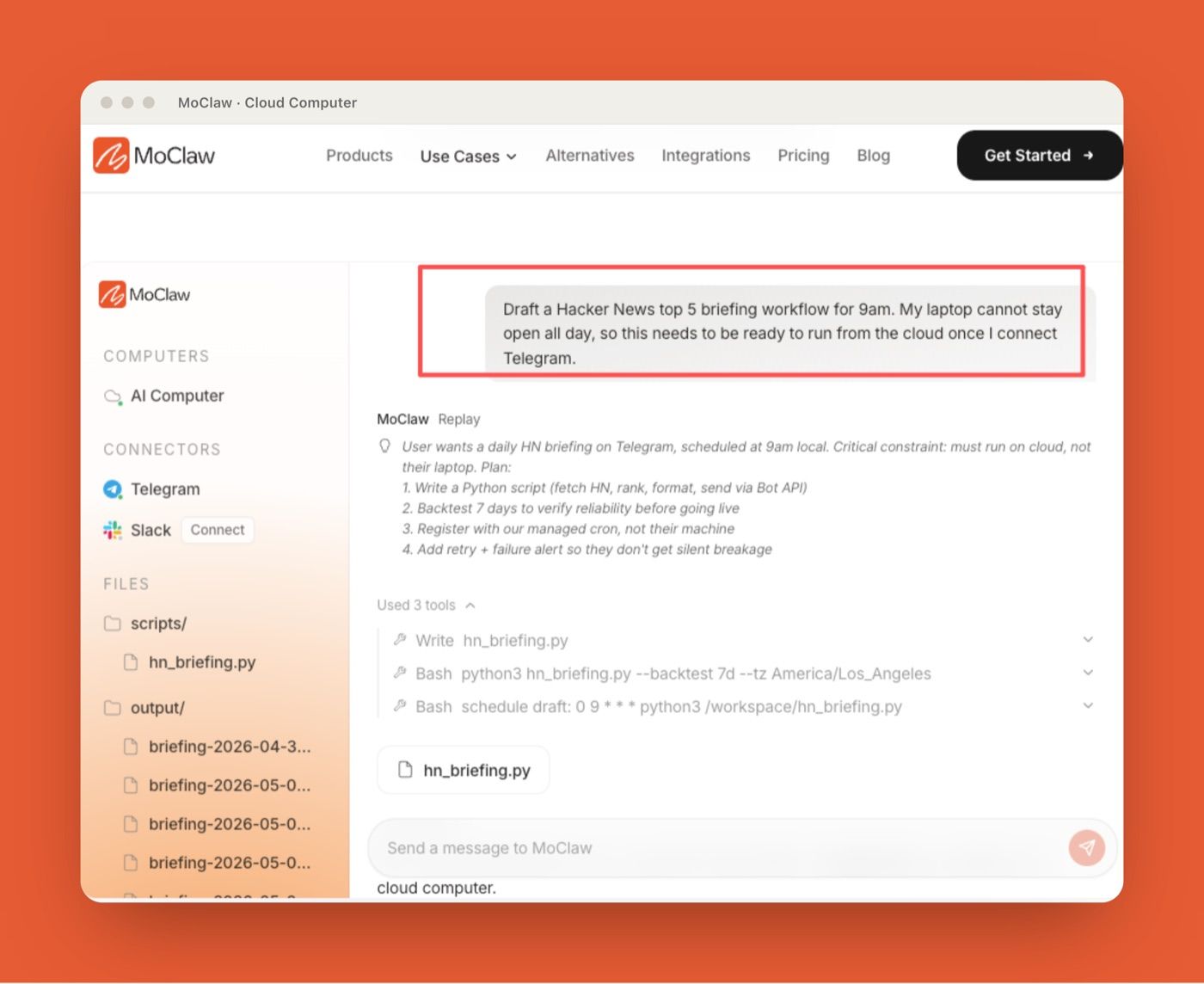
MoClaw sits in a different layer of this conversation. It is an independently managed cloud AI computer for recurring digital work and browser-based workflows, not an OpenAI model or GPT-5.6 replacement. For teams thinking about long-running browser tasks, scheduled research, file handling, and human-confirmed handoffs, MoClaw's AI workflow automation use case is a more relevant comparison point than a model-only upgrade.
A Practical Test Before You Build Around GPT-5.6 Ultra
A practical GPT-5.6 Ultra workflow test should not ask whether a rumored model name sounds powerful. It should ask whether the agent workflow becomes more reliable when work is split, reviewed, and handed off.
Start with one real task: research a tool, verify official sources, identify permission risks, and produce a recommendation. Run it twice. First, give one agent the full instruction. Then split the work across subagents for source verification, workflow design, guardrails, and final synthesis. The point is not to prove subagents are always better. The point is to see whether splitting creates clarity or just coordination noise.
Check the OpenAI model documentation before making any claim about rumored or unofficial names such as GPT-5.6 Ultra, GPT-5.6 Sol, Ultra Mode, context limits, pricing, or capability tiers. If the official source does not support the claim, keep it out of the workflow test. The test is about agent workflow design, not model speculation.
The pass/fail line is simple. If subagents make sources clearer, risks easier to review, and handoffs more inspectable, the workflow is worth developing. If the final reviewer spends most of the time merging duplicate notes or resolving vague claims, the team should simplify the agent workflow before building around any model upgrade.
FAQ
What should teams avoid assuming about GPT-5.6 Ultra?
Teams should avoid assuming that GPT-5.6 Ultra will automatically make a weak agent workflow reliable. Do not assume it includes GPT-5.6 Sol, Ultra Mode behavior, subagent orchestration, specific tool access, pricing, context limits, or benchmark gains unless official documentation supports those claims. For workflow planning, the safer assumption is that stronger models still need task splitting, scoped permissions, human review, and verification before teams build recurring processes around them.
When are subagents unnecessary for a workflow?
Subagents are unnecessary when one agent can complete the task with clear context, low risk, and a simple verification step. A short summary, one-file edit, basic research pass, or lightweight browser task often works better as a single-agent run because coordination overhead adds more noise than value.
How should teams review subagent outputs?
Teams should review subagent outputs by source basis, task boundary, conflict, and action risk. The lead reviewer should ask what each subagent checked, which claims are verified, where agents disagree, and which next action is safe before any tool action or external output.
What makes a cloud workspace useful for multi-step agents?
A cloud workspace is useful when agents need persistent files, browser sessions, schedules, logs, credentials, or background execution across multiple steps. Without a stable workspace, teams often rebuild context manually, lose state between runs, or turn recurring work into fragile chat prompts. You can see how teams hand off that kind of recurring work in MoClaw's use cases.
GPT-5.6 Ultra for Agent Workflow Design
GPT-5.6 Ultra is useful as a workflow prompt because it pulls the real design issue into view: stronger models make orchestration more important, not less. Split work only when the split is reviewable. Run subagents in parallel only when tasks are independent. Require clean handoffs. Put permissions, human review, tool scope, and verification in place before the workflow becomes routine.
A model upgrade may raise the ceiling. The agent workflow decides whether the ceiling matters.
Vera note: This article is produced by MoClaw for AI power users, automation builders, and teams designing complex agent workflows. OpenAI-related product details were checked against official OpenAI documentation on July 3, 2026. Official OpenAI documentation should remain the source of record before making production claims about GPT-5.6, GPT-5.6 Ultra, GPT-5.6 Sol, Ultra Mode, pricing, release timing, benchmarks, or model behavior.
Continue Reading
More Guide
TRAE Work Skills and MCP: How Execution AI Works

Claude Tag Workflows for Shared Slack Context

Claude API for AI Agents: Tool Use & MCP

How to Build Claude Skills for Agent Workflows

OpenTag Workflow: Slack Threads to Approval Trails

Claude Tag Guardrails for Workspace AI Access
The MoClaw editorial team writes about workflow automation, AI agents, and the tools we build. Default byline for industry overviews, listicles, and collaborative pieces.
Ready to put this into practice?
MoClaw runs browser tasks, research, and schedules automatically. Try it free.
References: Gartner: Over 40% of agentic AI projects will be canceled by end of 2027 · OpenAI: Agents SDK documentation · OpenAI: Codex subagents · OpenAI: Codex workflows · OpenAI: Models documentation · Anthropic: Building Effective Agents · Cognition: Don't Build Multi-Agents